Scaling Infra UX: Designing a Centralized Control Platform for 60K MAAS Sites
Context:
MAAS is Canonical’s bare metal provisioning tool used by enterprise and telco clients to manage thousands of machines.
As deployments scaled to 60,000+ edge sites across multi-region infrastructures, operators struggled with:
- Fragmented management across thousands of MAAS instances
- Manual, redundant image handling
- Delayed observability and no single source of truth
- Inconsistent UX between sites
I led the design of MAAS Site Manager — a centralized control platform to unify monitoring, troubleshooting, and configuration at scale.
Challenge: How might we empower organizations managing thousands of distributed MAAS instances to:
- Monitor site health in real time
- Push updates and fixes globally
- Control RBAC, networking, and profiles from a central UI
…without sacrificing scalability, security, or existing workflows?
My Role: Lead UX Designer, partnering with Product, Engineering, VPs, and Field Engineers.
- Directed two research rounds with 7 enterprise clients (Telco, Cloud, Retail)
- Mapped roles, RBAC, observability, and image/network automation requirements
- Designed centralized dashboard, image management, and LMA integration modules
- Created the first scalable infra control prototype for 60K+ sites
Impact:
- 6-week research & prototyping cycle → informed Canonical’s future Cluster Management product
- Introduced design patterns adopted across Cloud & Infra design system
- Provided an MVP concept that reduced image management time from hours per site to minutes centrally
- Enabled potential OPEX savings for cloud DB storage by eliminating redundant image duplication
Key Insights from Research: Interviewed 7 organizations: BT, VMware, AMD, Square, Home Depot, Tata, Canonical Bootstack.
Identified 3 core infrastructure archetypes:
- MEC Edge Clusters (Telco) – up to 60K micro-sites, each 5–15 machines, strict NOC integration needs
- Cloud Regions via AWS – semi-centralized deployments using AWS RDS as region controllers
- Region+Rack Setups – hybrid DC orchestration with multiple MAAS instances per site
Shared Pain Points:
- Redundant custom image uploads per site
- Lack of cross-site visibility and version consistency
- No streamlined RBAC or delegated management
- Delayed troubleshooting across geographies
Let’s look at different use cases:
Using Amazon AWS as a Region Controller
This use case is a from 2 of our external clients where they remove the need to manage Postgres themselves and create a semi-centralized MAAS setup by installing region controllers on Amazon AWS.
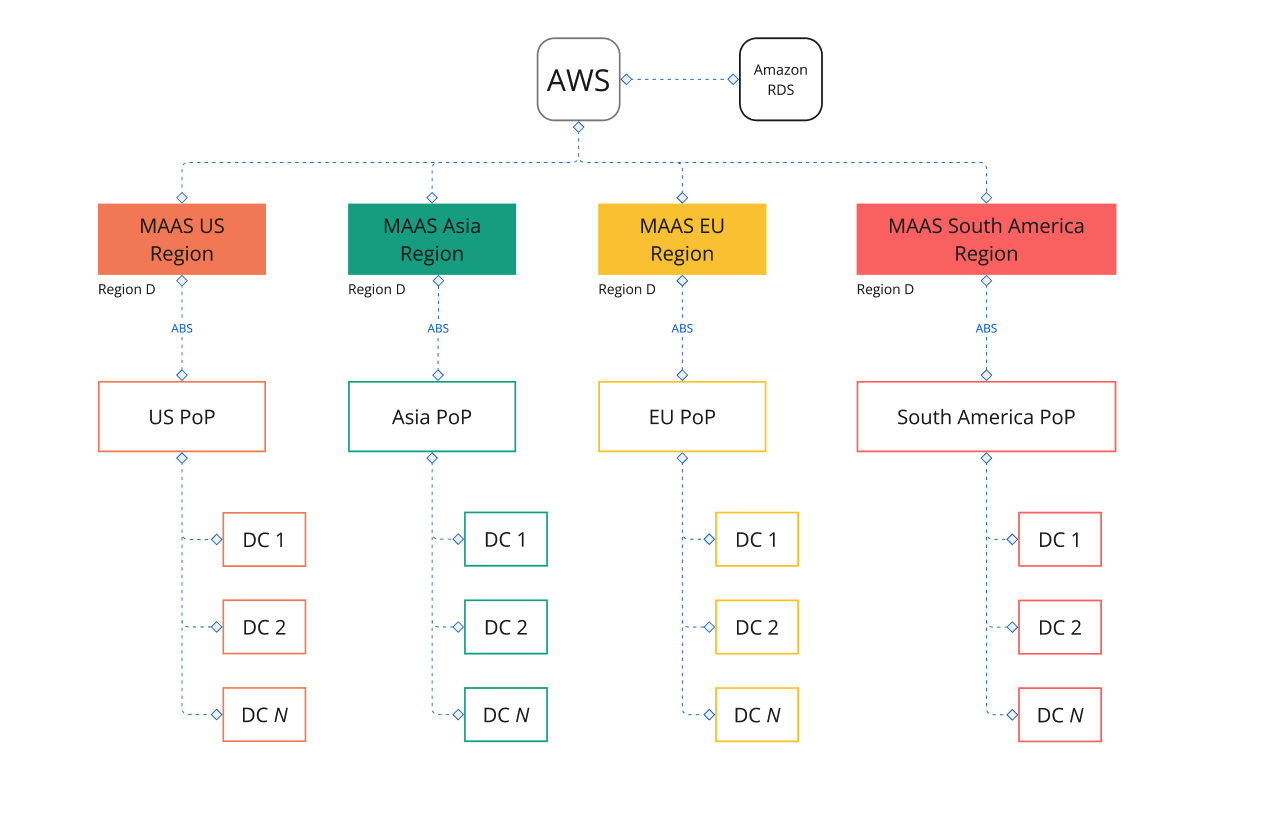
In this scenario, MAAS instances are distributed by multiple geographical locations around the world. MAAS instances act as a PoP (Point of Presence) for all data centers. In the more extreme cases, like this example, there can be 1000+ machines per Data Center. In total, they are managing around 10,000+ machines per PoP.
One of the biggest pain points here is Image Management, especially, custom images.
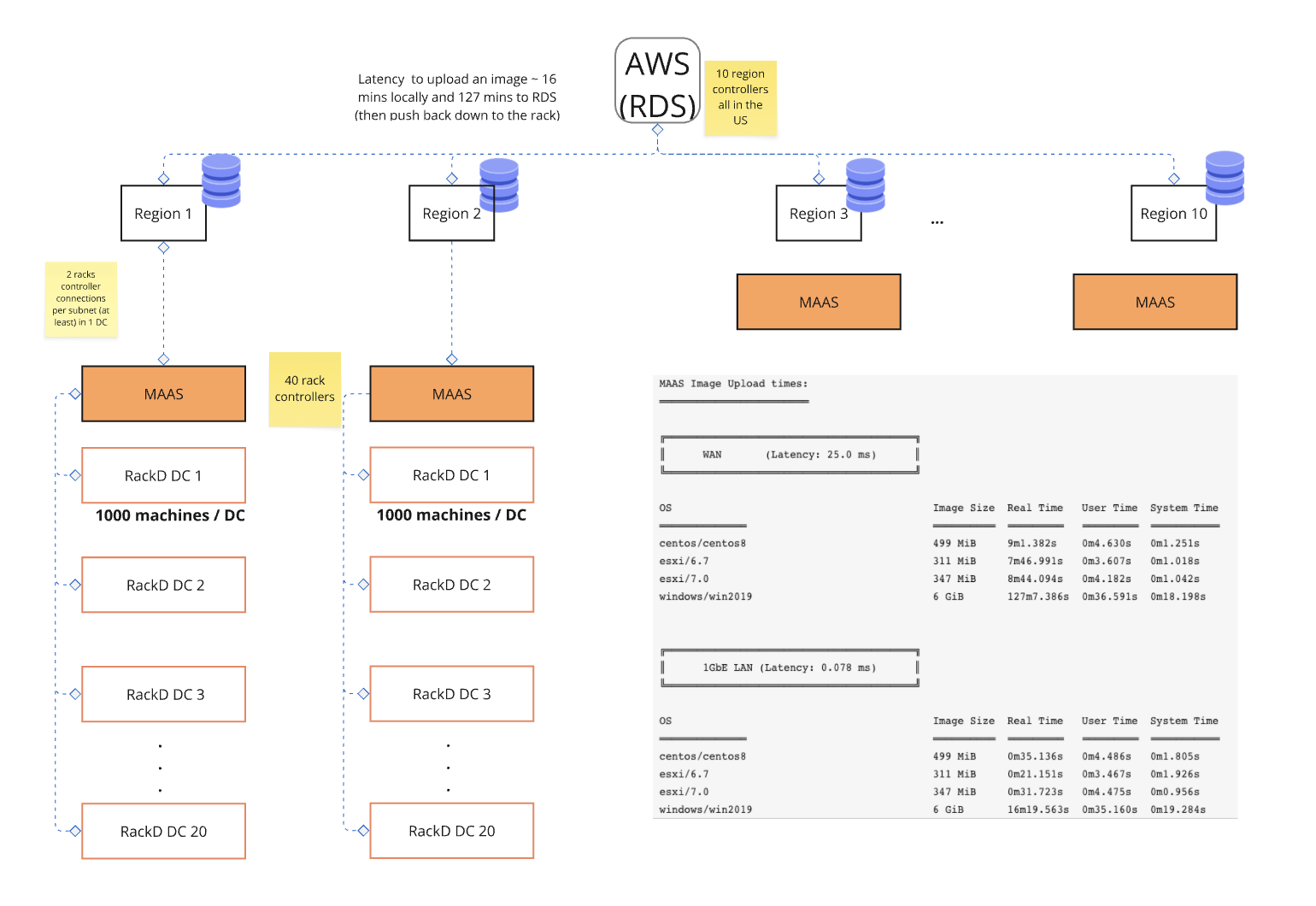
The current way to mange images require you to upload images to the region, then the images will get served to RDS. Then there is a synchronization process between MAAS and RDS, so all rack controllers in the PoP will have to download all images back from that database. As described in the image above, the latency to upload an image is ~16 mins locally and ~127 mins to RDS, plus pushing back down to the rack.
Going to the next PoP means the user needs to go through the exact same step.
There are 2 Problems here:
- Dealing with images is manual and redundant
- There is a lot of traffic of the same data being stored multiple times in the Database
- Database cost in the cloud is expensive, you have to either go into each MAAS instance’s table and clean the images or pay a really expensive price.
. . .
Using MAAS to manage high scale MEC sites
This is a common scenario amongst our Telco use cases. The Telco could use case is interesting because there are different purposes for Bare Metal that we have identified.
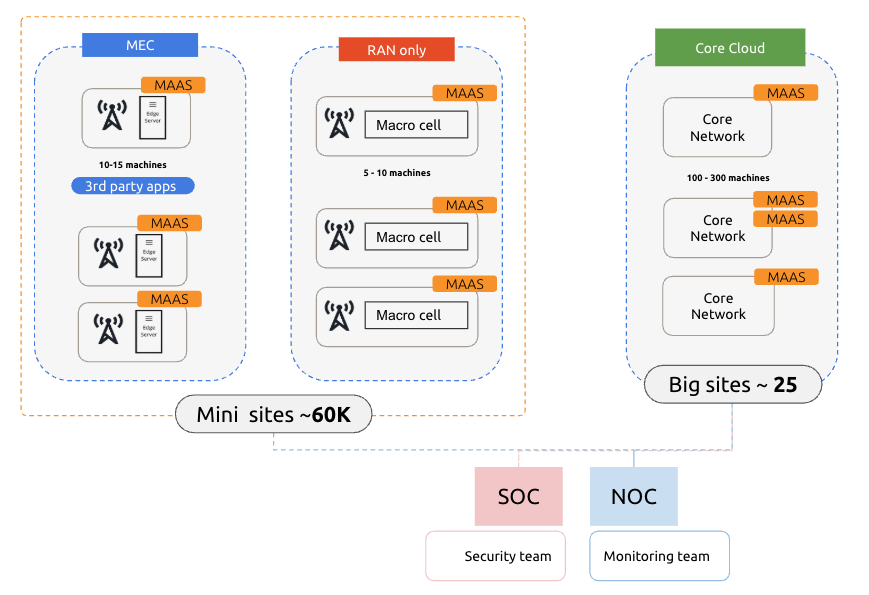
The first part is the mini sites called MEC (Multi-access Edge Computing) and RAN, where they install cell towers to the base stations. There are between 5-15 machines per site and one site respresents 1 MAAS instance. In this setup (for a particular external customer), they anticipated growing this mini-sites to around 60K sites all over the UK.
The second part is their core network, where they need this to run their services. In this example, there are between 100-300 machines per Core Site. A single Core Site could be governed by 1-2 MAAS instances. There are 25 core sites in total.
Given the current scale image management is still a problem, but instead of dealing with 10 MAAS instances, we’re talking about 25 core cloud sites + 60K mini sites.
Working with images in this case is quite difficult.
Aside image management, Telco users really cares about operation, monitoring, and troubleshooting guidlines as they have a very strict protocol for how to fix things and keeping everything in a state where it is well-maintained.
This is because if there is a power outage, it would be catastrophic if our phones don’t work.
Therefore, the important value here is they need to be able to plug any kind of manager to integrate with any systems like MAAS into their NOC.
. . .
Using MAAS as a Region+Rack controller
The last use case is our normal case where MAAS is a combined controller (Rack+Region controller).
In the first case, the client uses MAAS to test semi-conductors by creating a lab that connects 2 MAAS intances to 4 Data Centers. (As the image below)
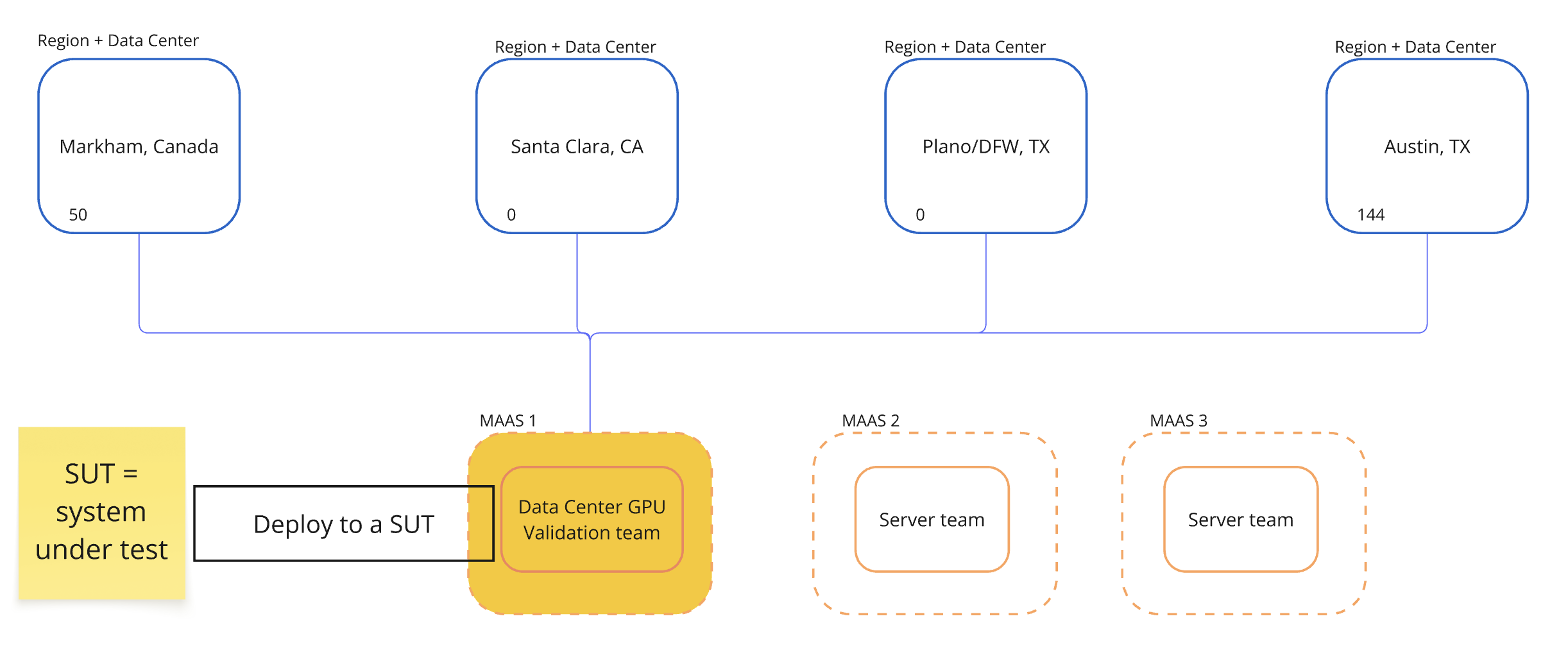
In the second scenario, the client is a department store in the US where they provision Data Centers with MAAS to serve multiple internal teams. There are 7 MAAS instances that are connected to 2 Data Centers. Cloudbold was a tool for workload orchestration where they serve machiens for internal teams like QA teams and security teams.
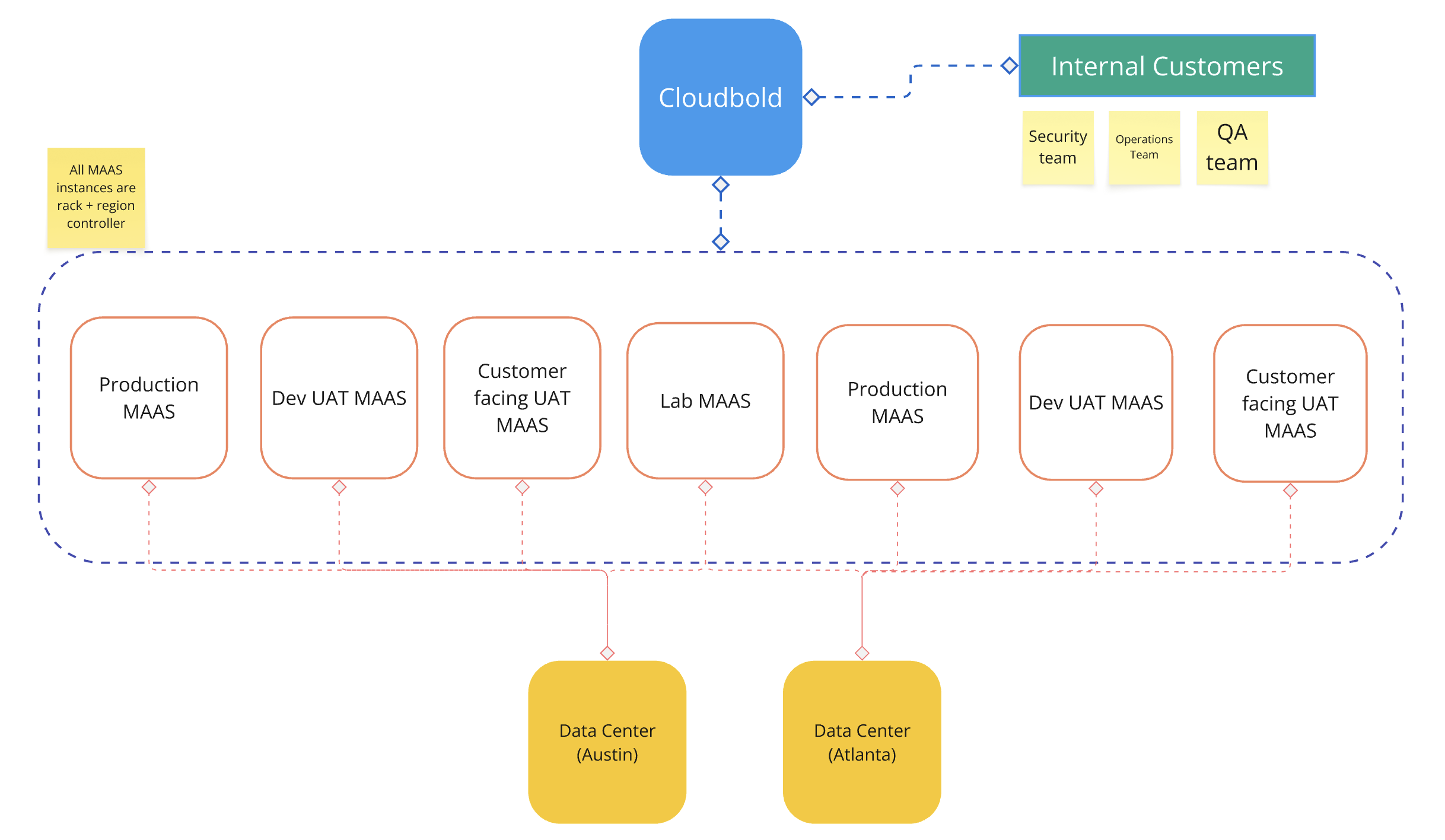
These 2 examples are companies with fewer sites but with multiple MAAS instances.
Image management is still a problem in this scenario because both companies care a lot about image synchronization and the ability to replicate custom images.
We didn’t really learn any new problems from this scenario in particular, aside from how they setup they MAAS instances.
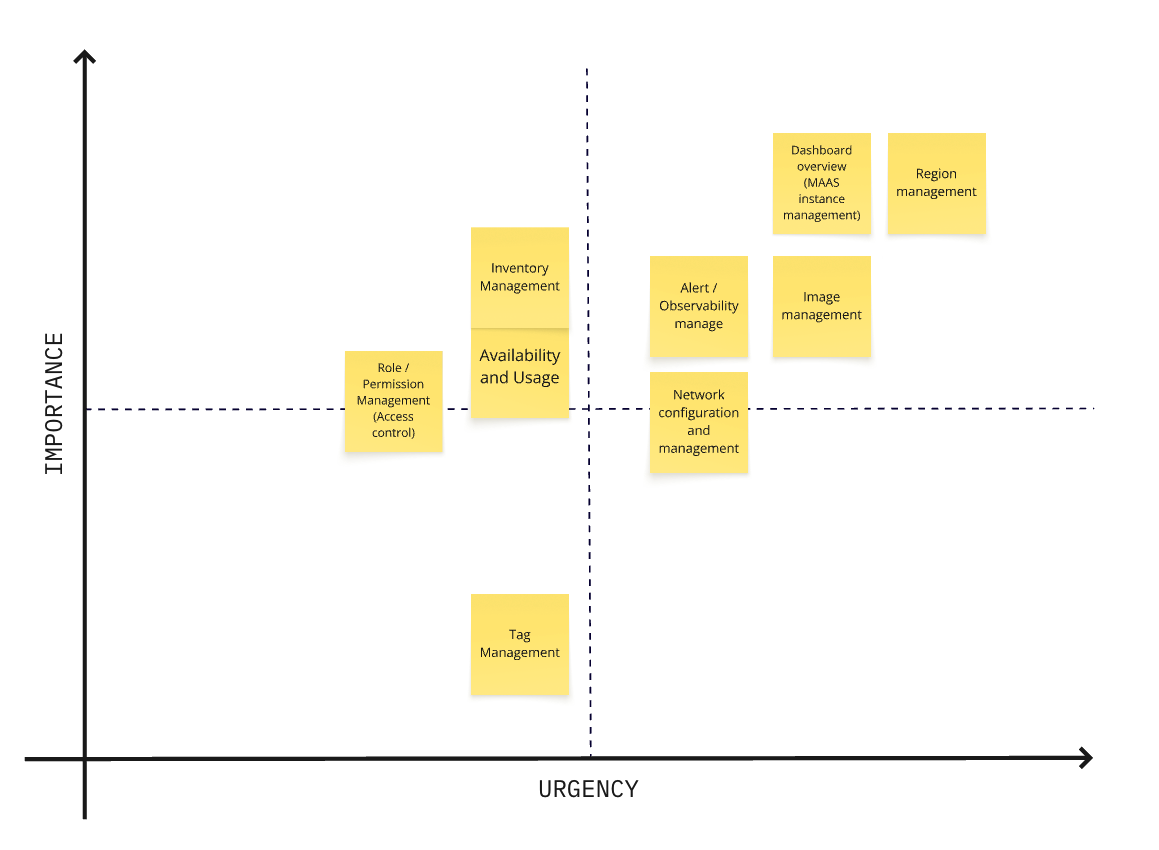
Learning about the three scenarios above, we mapped out the importance VS urgency graph based on the feedback as follows.
Concept Proposal (MVP Features):
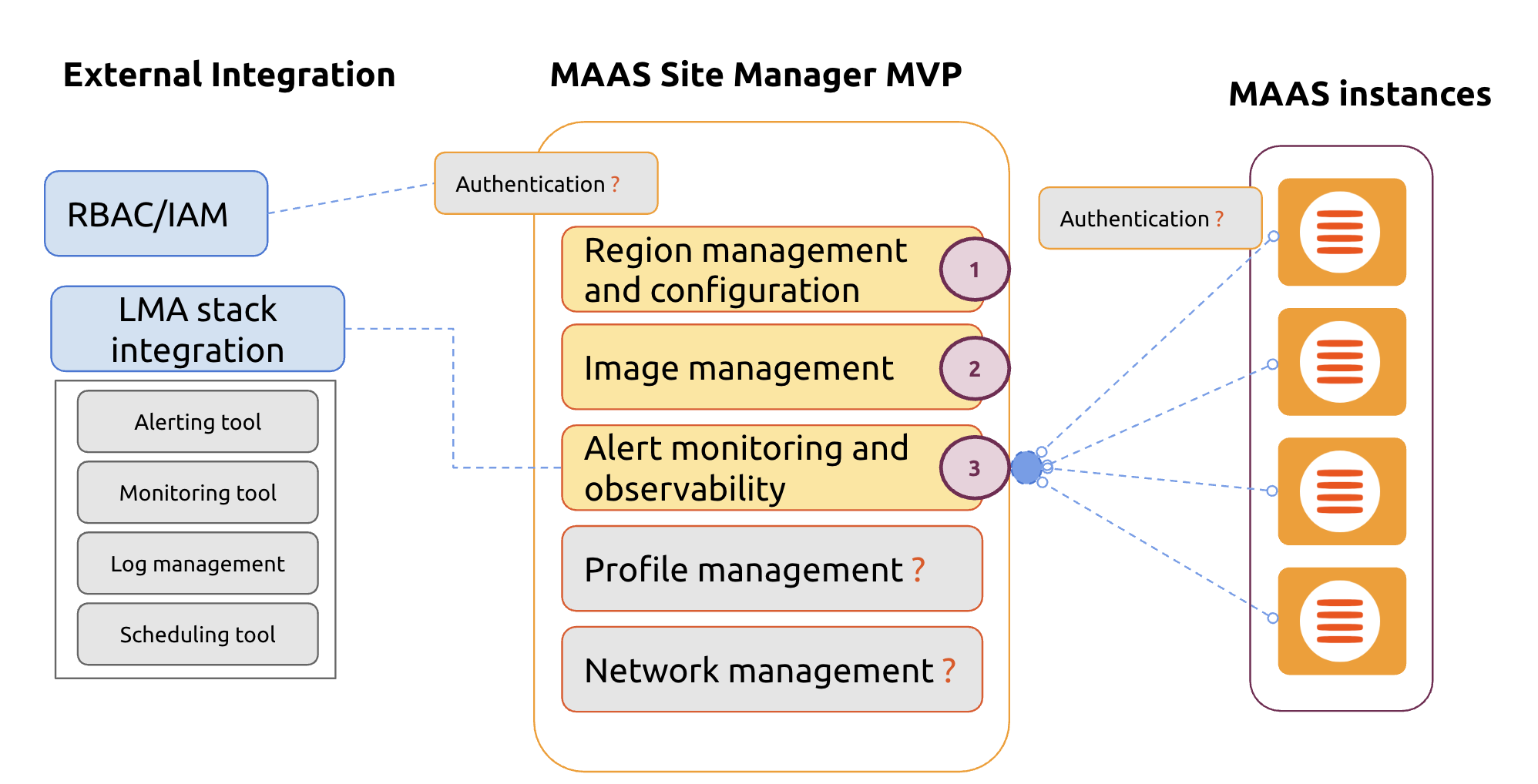
- Centralized Image Management – Single upload/distribution pipeline, deduplicated storage
- Multi-Scale Dashboard – Geolocation-based grouping for 60K+ sites, health/status at-a-glance
- LMA Stack Integration – Plug existing monitoring, logging, and alerting systems directly into Site Manager
- Networking & Profile Management – Centralized subnet, routing, and profile configuration
- Seamless Authentication – Trust-based MAAS-to-Site Manager integration to bypass repetitive sign-ins
Sneak Peek: First Prototype of MVP
This is a lightweigth prototype to show the concepts and components of MAAS Site Manager. This is not the final version, but a version to test out with our primary testing group.
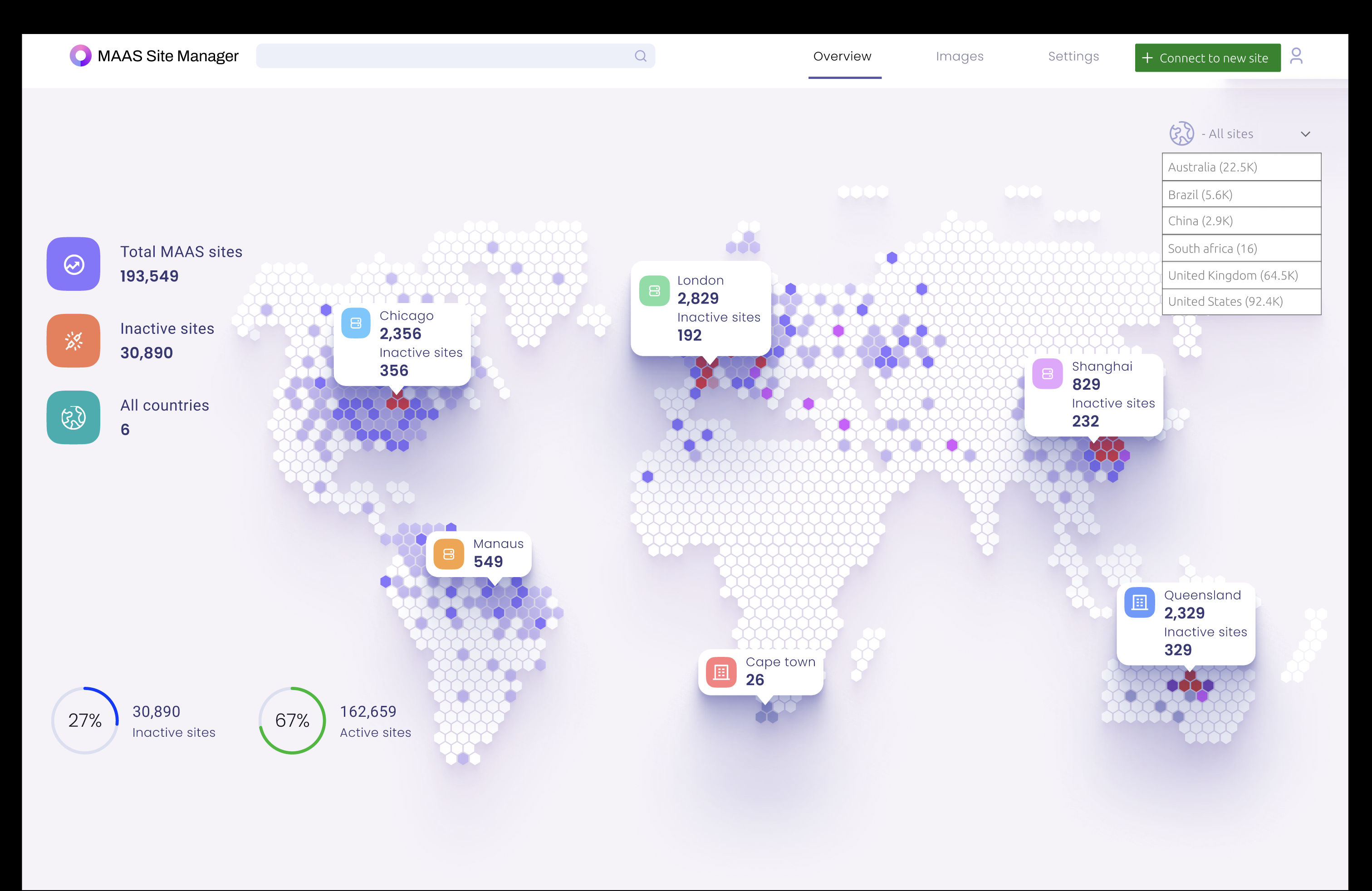
Dashboard
-
The main problem that the dashboard needs to solve is how to visualize site location in a scale of at least 60K+. It needs to allow people to group MAAS instances by region, location, or organizational structure.
-
There needs to be a way to show clustered map for at-scale visibility + status indicators,
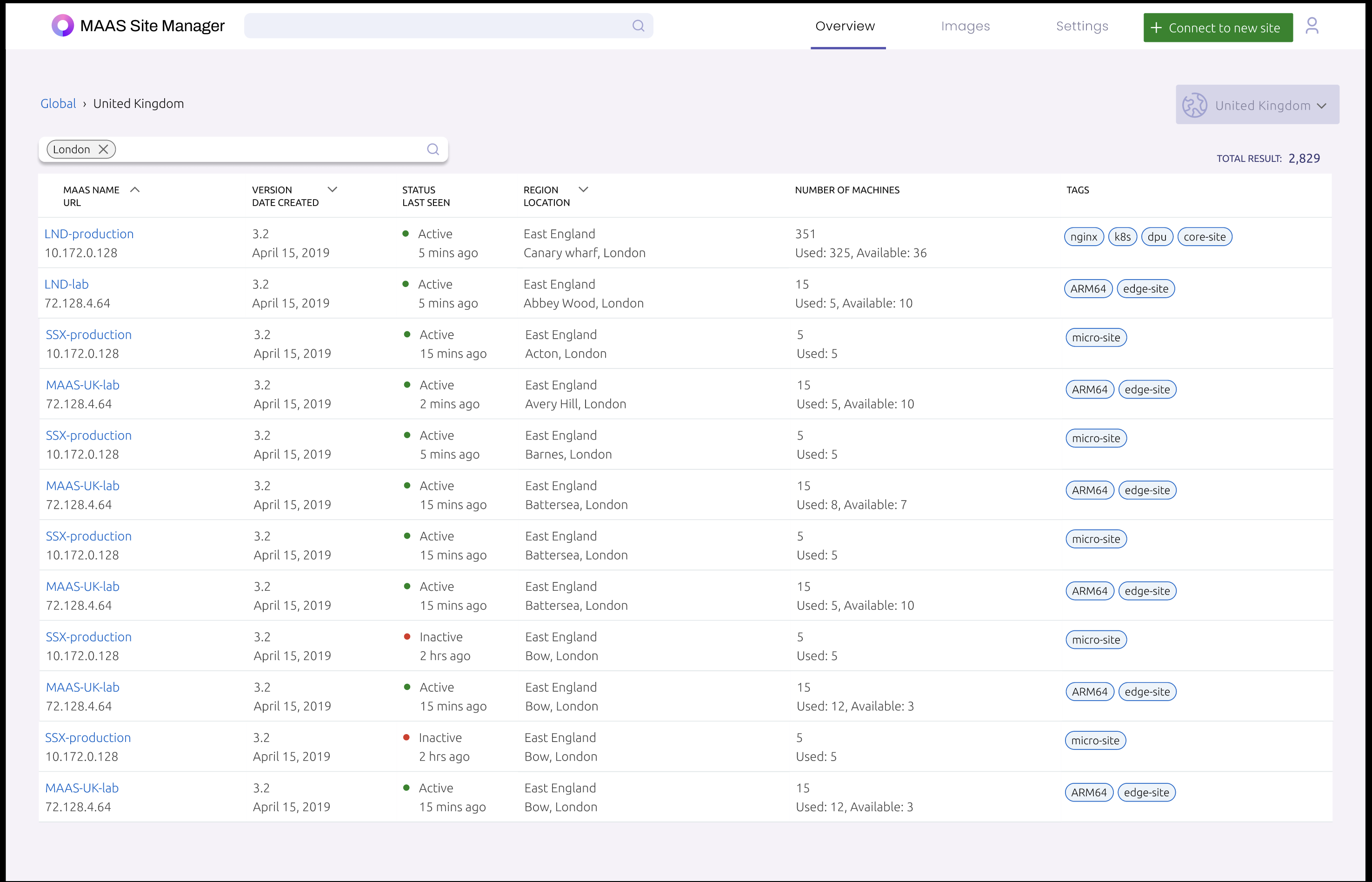
Listing View
- A user should be able to switch to a listing view and drill-down into any instance for machine-level management.
Initial Settings
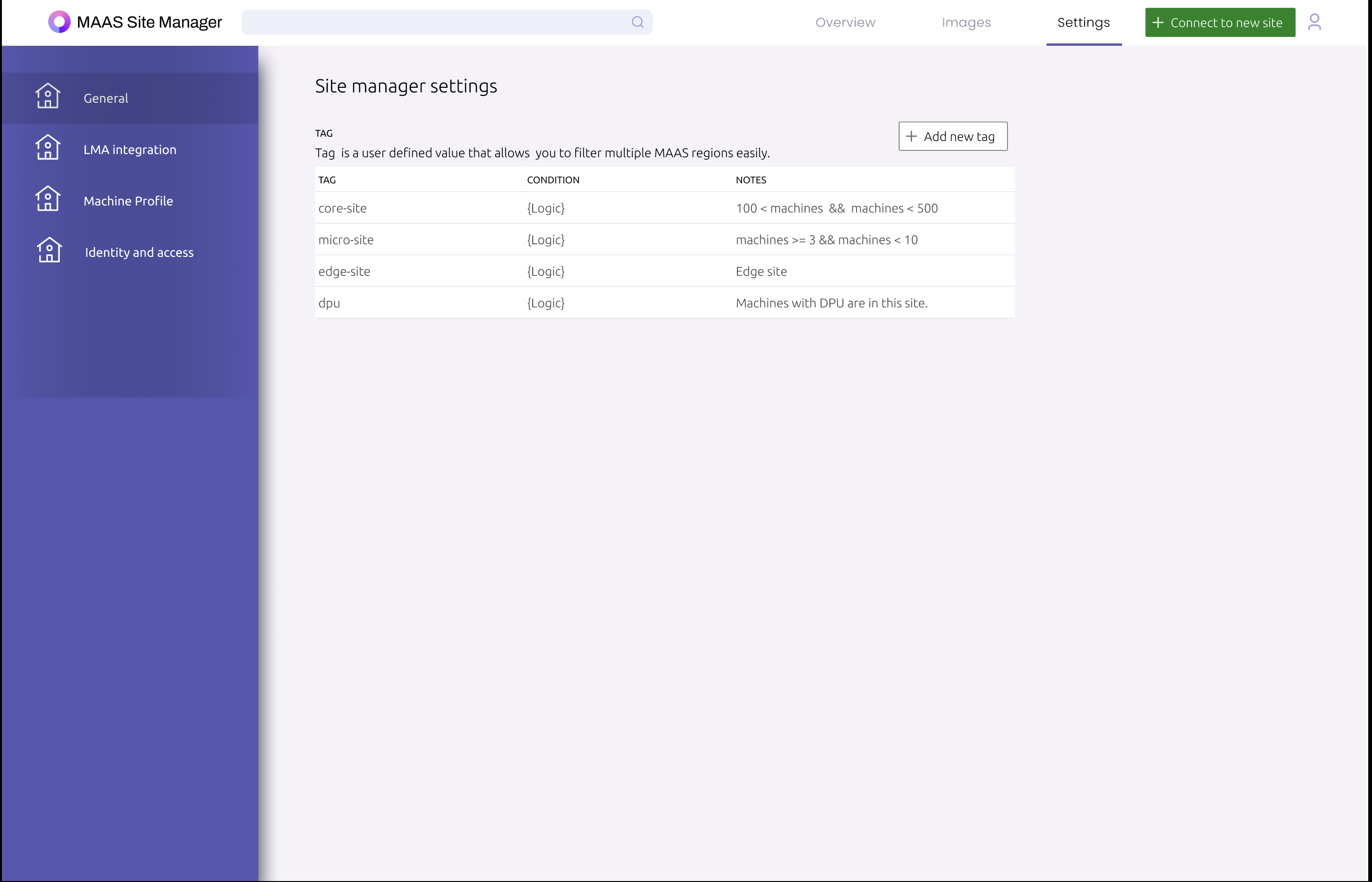
- The first prototype still requires more information from test users, so at this stage based on what we can pull is the automated tagging & filtering from MAAS API.
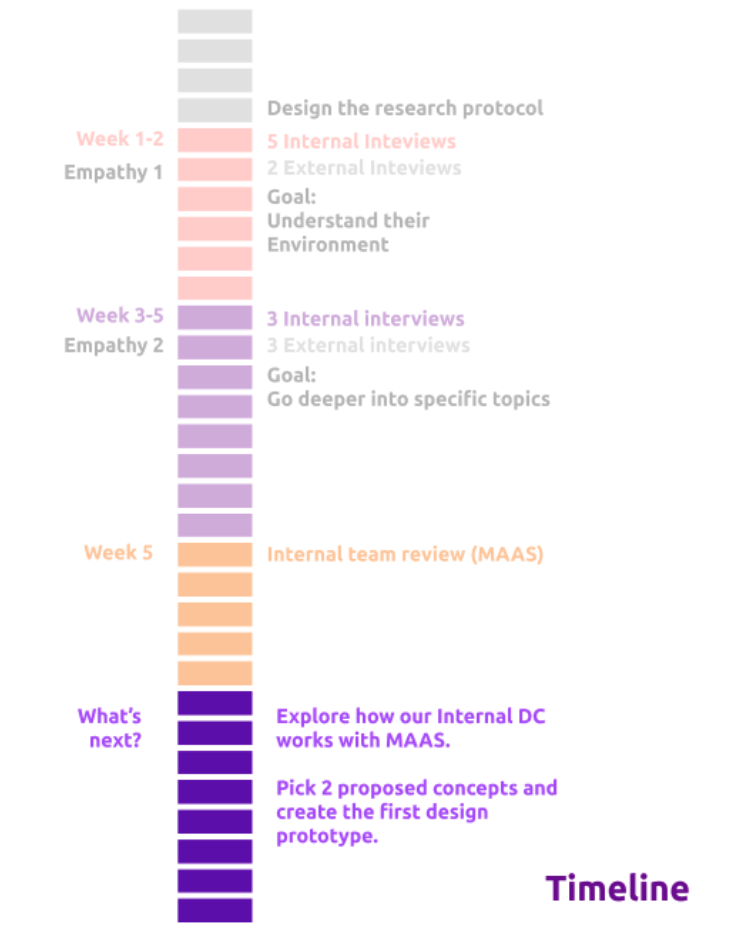
We spent a total of 6 weeks on this project to define the first conceptual MVP and a rough prototype.
Just because this is our first proposal we don’t want to stop here. There are a few things that we want to explore after this.
-
We would like to understand our internal DC Engineers: what they care about, how things are setup, and if there is a need for MAAS or MAAS Site Manager internally.
-
We want to pick 2 proposed concepts from the MVP and go really deep into the conceptual design, and create a very simple first prototype to test out our concepts.
Reflection & Learnings:
- At scale, infrastructure management is about visibility and delegation. Our users didn’t want more automation — they wanted control at a glance.
- Prototypes revealed the need for progressive disclosure: too much detail overwhelmed users; too little left them unsure.
- Designing for distributed systems UX requires aligning technical constraints with cognitive load
- Early prototyping can influence long-term product direction in infra platforms